One of the biggest criticisms of AI chatbots is that they make things up. Retrieval-Augmented Generation — RAG — is the technique the industry landed on to fix that. Here’s how it works and why it matters.
The Hallucination Problem
Large language models are trained to predict plausible text. Most of the time, plausible and accurate are the same thing. But sometimes the model generates confident, well-structured text that is factually wrong. This is called hallucination, and it’s one of the most important open problems in AI.
The traditional approach to solving this was to train bigger models on more data. That helps, but it doesn’t eliminate hallucination. The model is still fundamentally predicting text, not looking things up.
What RAG Does Differently
Retrieval-Augmented Generation takes a different approach. Instead of relying purely on what the model learned during training, RAG gives the model access to an external knowledge base at query time.
Here’s the basic flow:
- A user asks a question
- The system searches a document store for relevant information
- The retrieved documents are inserted into the prompt alongside the question
- The LLM generates an answer. generates an answer grounded in those documents
The model is no longer working from memory alone — it has the relevant source material right in front of it, the same way a researcher would work with reference documents rather than trying to recall everything from memory.
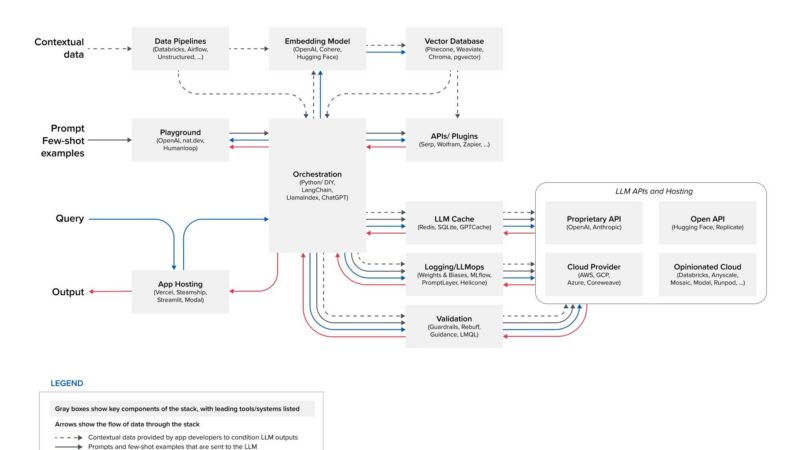
The Key Components
The document store is where your knowledge lives. This could be a collection of PDFs, a knowledge base, a database of articles, or any structured repository of information.
The retrieval system is responsible for finding the right documents when a query comes in. Most modern RAG systems use vector search — documents are converted into numerical representations (embeddings) that capture their semantic meaning. When a query arrives, it’s converted to the same format and the system finds the most similar documents by comparing vectors.
The LLM receives both the query and the retrieved documents, then synthesizes an answer that’s grounded in the source material.
Where RAG Works Well
RAG is particularly effective for:
Enterprise knowledge management — letting employees query internal documents, policies, and procedures in natural language.
Customer support — grounding AI responses in actual product documentation to reduce errors.
Research assistance — helping users navigate large bodies of literature.
Up-to-date information — since the retrieval layer can be updated independently of the model, RAG systems can access current information even if the underlying LLM has an older training cutoff.
Where RAG Still Struggles
RAG is not a complete solution. Common failure modes include:
Retrieval failures — if the right document isn’t retrieved, the model works with incomplete context and may still produce errors.
Context window limits — you can only fit so many documents into a prompt. For complex questions requiring many sources, this becomes a bottleneck.
Conflicting sources — when retrieved documents disagree with each other, the model can struggle to adjudicate between them.
Multi-hop reasoning — questions that require connecting information from multiple documents in a chain of reasoning are still challenging.
RAG in 2026
The RAG landscape has evolved significantly. Early implementations were straightforward vector search plus generation. Today’s systems incorporate reranking, hybrid search combining keyword and semantic retrieval, and more sophisticated chunking strategies.
Agentic RAG systems can now decide when to retrieve, what to retrieve, and whether retrieved information is sufficient — or whether they need to search again with a different query.
For anyone building with LLMs, RAG remains one of the most practical and well-understood techniques for improving reliability. If you’re deploying an AI application where accuracy matters, it almost certainly belongs in your stack.
stored in vector databases.Related: how to build a RAG system and deep dive into embedding models and vector databases.