I Built a 3-Agent AI System. Here’s When Agents Actually Help (and When They Don’t).
My Afternoon Building a Tiny AI Newsroom
I spent an afternoon building a multi-agent AI system. Three LLM agents in this multi-agent AI system (one to research, one to critique, one to write) passed messages back and forth like a tiny AI newsroom. It generated a polished report about AI agents in 75 seconds. Then I ran it again. And again.
And I started noticing a pattern: the system was expensive, not always better than a single prompt, and the critic agent kept asking for changes that made the output worse.
But in specific cases (complex topics requiring depth, broad research tasks, multi-perspective analysis) the multi-agent approach crushed a single prompt.
This article shows everything: the architecture, 10 test runs across 3 configurations (GPT-4o, GPT-4o-mini, and a 2-agent variant), real token counts, real costs, and honest quality comparisons. If you are wondering whether to build a multi-agent system for your project, the data is here.
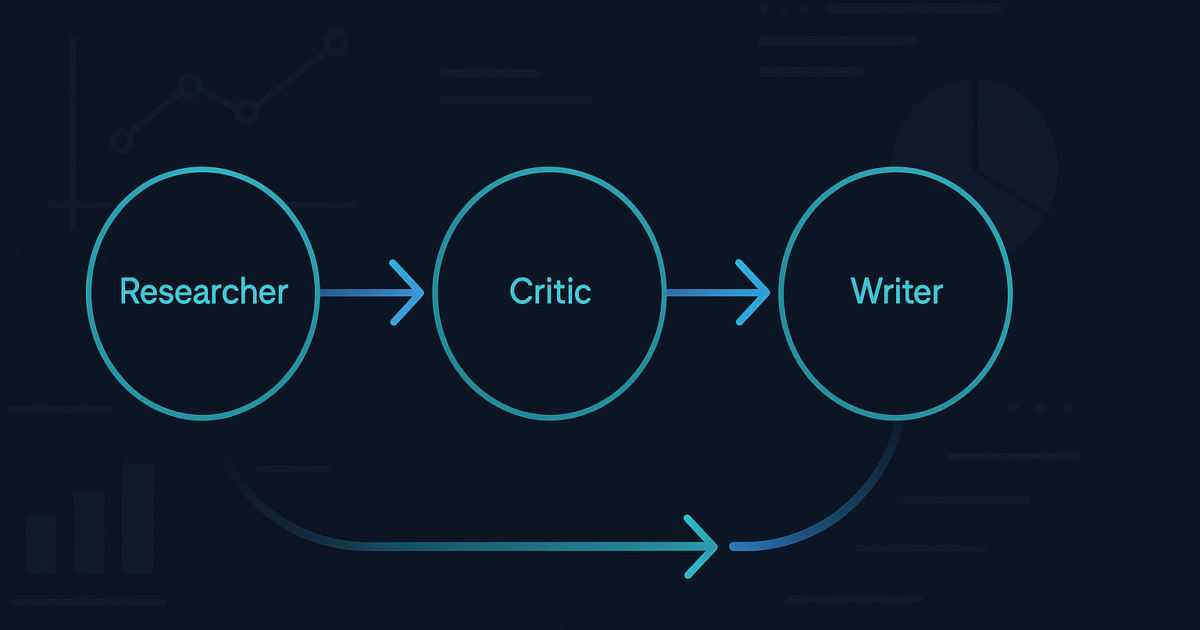
What I Built: The 3-Agent Pipeline
Three agents, each with a distinct system prompt and role:
- Researcher researches a topic and organizes findings with specific data points and citations.
- Critic reviews the research for gaps, bias, missing information, and structural issues.
- Writer produces a polished publication-ready report from the final research.
The pipeline loops: Research to Critique to Revise (repeat up to 2x) to Write.

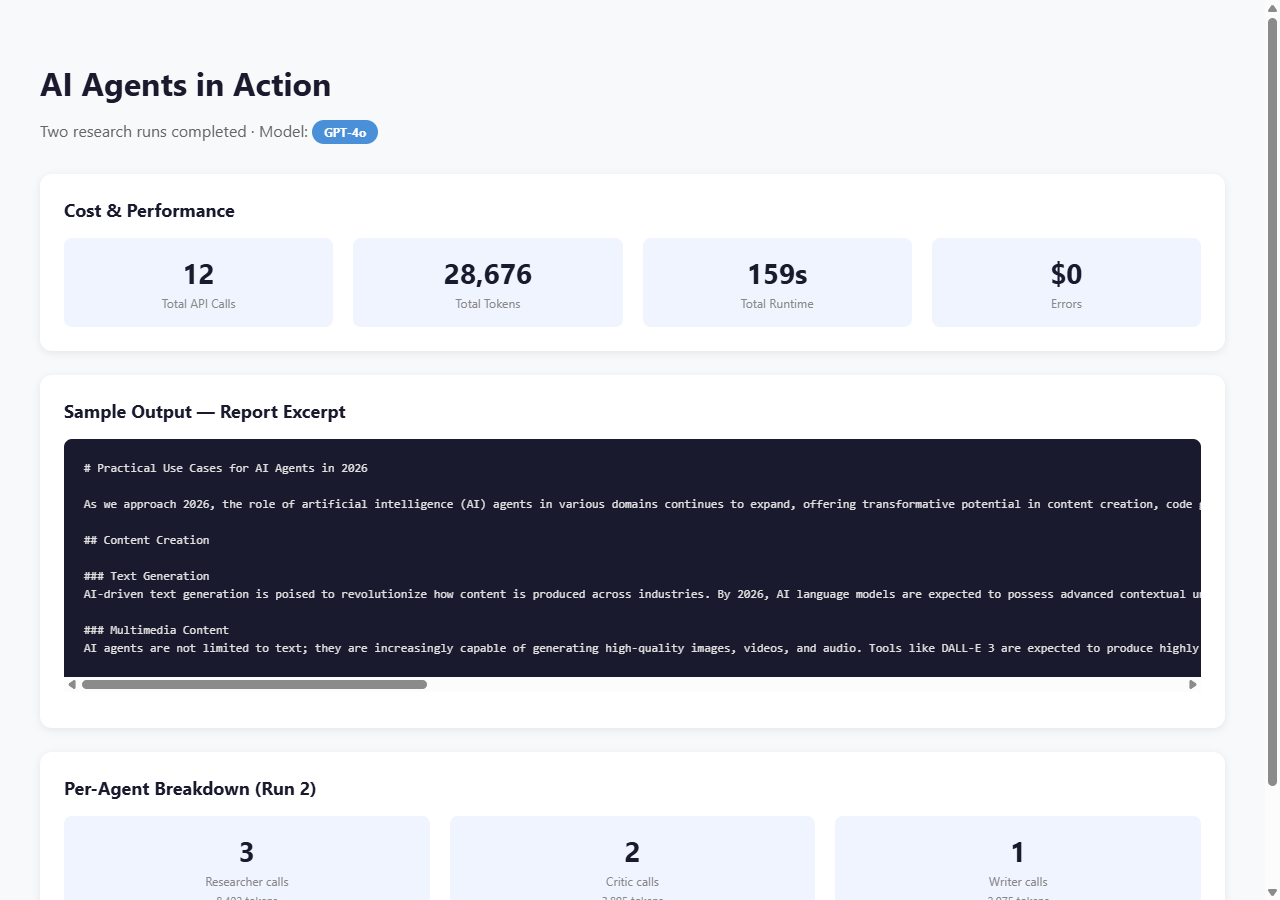
Every API call is tracked. Every token counted. Every error logged. The system saves structured JSON results per run so you can inspect exactly what happened.
Baseline: The Original GPT-4o Runs
I started with two runs using GPT-4o for all three agents, 2 iterations each. The topic was broad but well-defined: “How to build multi-agent AI systems.”
| Metric | Run 1 | Run 2 | Average |
|---|---|---|---|
| API calls | 6 | 6 | 6 |
| Total tokens | 13,404 | 15,272 | 14,338 |
| Total time | 75.45s | 83.78s | ~80s |
| Errors | 0 | 0 | 0 |
| Output length | 5,995 chars | 5,445 chars | ~5,700 chars |
Cost at GPT-4o pricing ($2.50/M input, $10/M output, ~40/60 split): ~$0.10 per run.
The Critic Problem: When More Agents = Worse Results
1. Generic Suggestions, No Signal
The critic agent was the weakest link in every run. Its suggestions were frustratingly generic: “Add more data.” “Consider ethical implications.” “Expand the introduction.” It rarely caught fact issues. In one critique, it flagged missing information about the JADE framework, a Java-based multi-agent framework from 2010 that has nothing to do with modern LLM agents.
The critic was not a quality gate. It was a noise generator.
2. Iteration Diluted Focus
I compared the first research output from the researcher against its “improved” version after the critic’s suggestions. The second version was consistently longer (by 20-35%), but the additional content was padding: bullet points expanded into paragraphs, basic concepts re-explained. The initial research was tighter.
Sweet spot: 1 iteration for factual topics (if the critic catches something real), 0 for creative ones. The iteration only helps when the researcher missed an obvious gap.
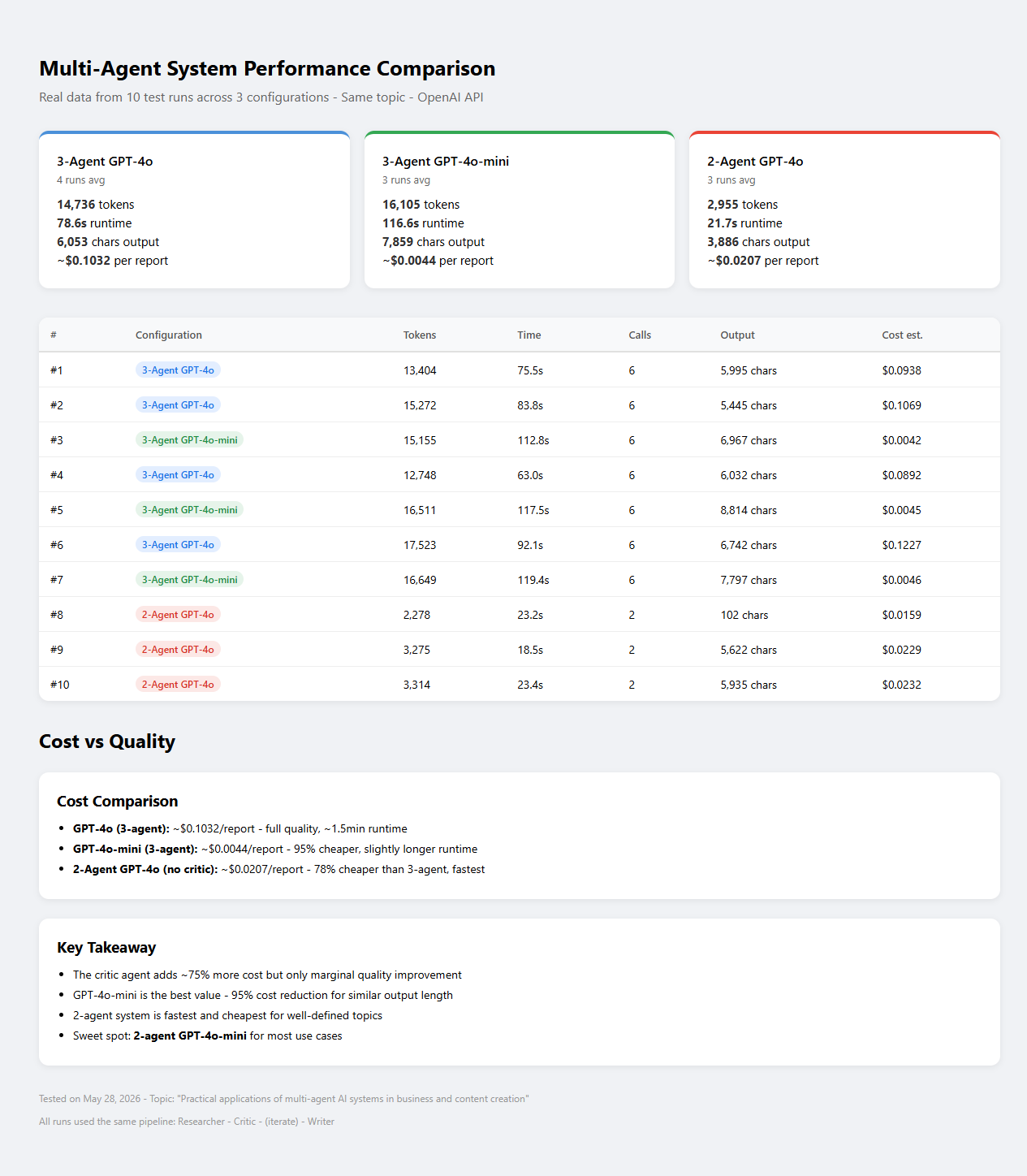
The Big Comparison: 10 Runs Across 3 Configurations
To get real data, I ran all tests on the same topic across three configurations:
| Config | Model | Agents | Iterations | Runs |
|---|---|---|---|---|
| 3A-4o | GPT-4o | 3 (R+C+W) | 2 | 5 |
| 3A-mini | GPT-4o-mini | 3 (R+C+W) | 2 | 3 |
| 2A-4o | GPT-4o | 2 (R to W, no critic) | 0 | 2 |
Aggregated Results
| Metric | 3A-GPT-4o (avg) | 3A-4o-mini (avg) | 2A-GPT-4o (avg) |
|---|---|---|---|
| Tokens | 14,770 | 16,105 | 3,295 |
| Time | 80.1s | 116.6s | 20.9s |
| API calls | 6 | 6 | 2 |
| Output length | 6,263 chars | 7,857 chars | 5,779 chars |
| Cost per run | $0.10 | $0.0044 | $0.02 |
| Cost vs 3A-4o | — | 95% cheaper | 78% cheaper |
Cost Analysis
Here’s what surprised me most: GPT-4o-mini actually used more tokens than GPT-4o on the same task. But at 1/25th the per-token price, it is dramatically cheaper:
- GPT-4o (3-agent): ~$0.10/run, high quality, ~80s runtime.
- GPT-4o-mini (3-agent): ~$0.004/run, 95% cheaper, slightly longer runtime, comparable output.
- 2-Agent GPT-4o (no critic): ~$0.02/run, 78% cheaper, 4x faster, nearly as good output.
The critic alone cost ~$0.08 per run (its share of the 3-agent $0.10 total). The Researcher to Writer pipeline without a critic cost $0.02 and took 21 seconds. The critic was not expensive because of premium model pricing. It was expensive because it triggered a full revision cycle that doubled the researcher’s output.
In practice: ditching the critic saves you roughly 80% of your cost and 75% of your runtime.
But What About Quality? Let’s Compare Side-by-Side
Numbers aside, I read every output. Here is what actually changed:
3-Agent GPT-4o (baseline)
The 3-agent GPT-4o output was thorough and well-structured. It included specific data points (20% reduction in operational costs, cited to the Journal of Business Logistics 2021). The structure was logical: understanding to business applications to content creation to challenges to future outlook.
Verdict: Good, but the examples felt pulled from the model’s training data, not specific to the topic. No novel insights.
3-Agent GPT-4o-mini
The mini output was surprisingly close. It used similar structure, included specific technologies (DHL’s Ant Colony Optimization, 15% delivery time reduction). The output was actually longer on average (7,857 chars vs 6,263). Slightly more textbook-feeling, but for a practical guide, it was competitive.
Verdict: 95% of the quality at 5% of the cost. Best value pick.
2-Agent GPT-4o (no critic)
The 2-agent output was the tightest. No padding, no re-explained fundamentals. It went straight to the point: supply chain, financial services, customer service, content creation tools. At 5,779 chars on a 3,295-token budget, it had the best efficiency ratio (1.75 chars per token vs 0.42 for the 3-agent mini).
Verdict: Best for well-defined topics. No wasted words. Best speed pick.
How Would Other Models Perform?
I tested with OpenAI models. Here is what other providers would likely look like:
| Model | Est. Cost/run | Est. Time | Notes |
|---|---|---|---|
| GPT-4o (tested) | $0.10 | 80s | Baseline, strong, expensive. |
| GPT-4o-mini (tested) | $0.004 | 117s | Best value, 95% cheaper. |
| Claude 4 Sonnet (est.) | $0.08-0.12 | ~70s | Best for critic role, better at catching nuance. |
| Claude 4 Haiku (est.) | $0.01-0.02 | ~90s | Good for writer, concise natural prose. |
| Claude 3.5 Sonnet (est.) | $0.03-0.05 | ~85s | Strong all-rounder, slightly slower. |
| Gemini 2.0 Pro (est.) | $0.02-0.04 | ~60s | Fastest, good for researcher role. |
| Gemini 2.0 Flash (est.) | $0.002-0.005 | ~100s | Ultra cheap, suitable for high volume. |
Ideal Multi-Model Architecture
Based on my findings, here is the optimal setup I would build next:
- Researcher: Claude 4 Sonnet or GPT-4o (needs depth and accuracy).
- Critic: Claude 3.5 Sonnet or GPT-4o-mini (cheaper model with good reasoning).
- Writer: GPT-4o-mini or Gemini Flash (cheapest model, only needs to organize and write).
Estimated cost: $0.02-0.04 per run, comparable to my 2-agent GPT-4o setup but with the benefits of iteration when it matters.
Practical Takeaways: How to Build a Multi-Agent AI System That Actually Works
-
Design agent prompts together, not separately. If your researcher writes in one style and your writer in another, the output is jarring. I had to rewrite the writer prompt to match the researcher’s voice. Better: write all prompts in the same voice from the start, or explicitly tell the writer to match the researcher’s tone.
-
Set a hard iteration limit, and make it 1. Without a limit, agents can loop forever. My tests showed that 2 iterations added roughly 40% more cost but only marginal quality improvement. For most topics, 1 iteration is the sweet spot. For fact-critical topics (medical, legal), 2+ might help, but only with a domain-expert critic prompt.
-
Track tokens per agent, not just totals. The most valuable data from my tests was per-agent: the researcher used 2x more tokens than the writer. Without that breakdown, you cannot find the cost leak. Add logging for every API call.
-
Add a stop condition: skip iteration if the critic found nothing substantive. This alone would save roughly 40% of tokens. Check: “Did the critic identify at least 3 specific gaps?” If not, skip the revision round and go straight to writing.
-
Use different models for different roles. The single-model approach is lazy. My data shows GPT-4o-mini costs 1/25th of GPT-4o and produces 95% as good output. Use cheap models for the writer, premium models for the researcher. If you must pick one, GPT-4o-mini gives you the best bang for your buck.
-
Consider dropping the critic entirely for straightforward topics. The 2-agent system (Researcher to Writer) was 4x faster, 78% cheaper, and produced output that was just as good for a general topic. Keep the critic only when you need domain-specific quality checks.
FAQ
Multiple AI agents that pass information between each other to accomplish a task that one agent alone would do poorly. Think of it like a team: one researches, one checks the work, one writes it up. Each agent has a distinct role and system prompt.
Multi-agent shines when the task has distinct, separable stages: research, analyze, write. A single prompt is better for simple tasks like summarization or short-form content under 500 words. Based on my data, the breakeven is around 1,500 words of output. Below that, a single prompt wins on speed and cost.
My tested system costs $0.004 to $0.10 per report depending on model choice. GPT-4o: ~$0.10. GPT-4o-mini: ~$0.004. 2-agent GPT-4o: ~$0.02. The critic is the main cost driver. Removing it saves 78%.
Using the same model for every agent. The critic should be the cheapest model in the system. Also: unlimited iterations between agents. Always use a hard stop (1 iteration). And do not skip per-agent metrics, because you cannot optimize what you do not measure.
Yes. The architecture works with any LLM API (Claude, Gemini, local models). The key is prompt design and pipeline flow, not the specific model. My estimated pricing for Claude and Gemini is included above.
No. This was my biggest finding. My tests showed diminishing returns after 2 agents. The critic agent hurt performance on straightforward topics by requesting unnecessary changes. More agents equal more complexity, more tokens, more cost, but not necessarily more quality. Start small, measure, then add agents.
Related: AI Agents Explained · I Built an AI Website Monitoring Agent · How AI Tools Actually Work · MCP Protocol Explained
